Exploring memory allocation on Linux Kernel
My recent exploration to understand more about Linux kernel memory allocation was purely a coincidental one.
It started off with a recent event where I was debugging a piece of code which left me quite puzzled. The minimized code in question is listed below:
// this buffer will be passed into the function tdx_extend_rtmr
static u8 digest[DIGEST_SIZE] __aligned(64);
/* ------------------------------------------------------------------ */
/* Inline helper – extend RTMR[index] with 48‑byte digest via TDCALL */
/* ------------------------------------------------------------------ */
static int tdx_extend_rtmr(u8 index, void *buf)
{
phys_addr_t gpa = virt_to_phys(buf);
u64 ret;
register u64 rax asm("rax") = TDG_OP_RTMREXTEND;
register u64 rcx asm("rcx") = gpa;
register u64 rdx asm("rdx") = index;
register u64 r10 asm("r10");
/* TDCALL opcode: 0x66 0x0F 0x01 0xCC */
asm volatile(".byte 0x66, 0x0f, 0x01, 0xcc"
: "+a"(rax), "=r"(r10)
: "c"(rcx), "d"(rdx)
: "memory",
"r8", "r9", "r11",
"r12", "r13", "r14", "r15");
ret = rax; /* error code returned in RAX; 0 == success */
if (!ret) {
// if no error, check r10 for the leaf specific error if any
ret = r10;
if (ret) {
pr_err("tdx-extend-rtmr: Leaf error code: %llx\n", ret);
}
}
return ret ? -EIO : 0;
}
When using a VM running with Intel TDX extensions enabled, it is possible to extend its runtime measurement register (RTMR) using a tdcall. The way it works is quite similar to doing a hash extension into a vTPM PCR. However, I faced a very puzzling problem whereby despite following the specifications of the tdcall correctly (using a 64-byte aligned buffer, converting the virtual address to a physical address), I was getting unexpected results in my RMTR. In particular, even though i changed the hash in the digest buffer on each boot, the RTMR value was consistently extended with the same value.
To give a concrete example of what happened across 3 reboots, here are my kprintfs:
[ 62.856543] sha384 digest: 32aa829d20ea35bd89325a38aed5ece6a50a1a354f89a023d7873021f9cc437f93c3ee52d53a804c8d6d9b40f7f7dfbd
RTMR 3: [245, 123, 183, 237, 130, 198, 174, 74, 41, 230, 201, 135, 147, 56, 197, 146, 199, 212, 42, 57, 19, 85, 131, 232, 204, 190, 57, 64, 242, 52, 75, 14, 182, 235, 133, 3, 219, 15, 253, 106, 57, 221, 208, 12, 208, 125, 131, 23]
-------------------------------------
[ 65.758341] sha384 digest: 178229243b7c233bdbb8a041306dc6faab85f92dacb07a625b04ff1c9496e530ca904f6a32a6e03e1879c8cb6fedd1ee
RTMR 3: [245, 123, 183, 237, 130, 198, 174, 74, 41, 230, 201, 135, 147, 56, 197, 146, 199, 212, 42, 57, 19, 85, 131, 232, 204, 190, 57, 64, 242, 52, 75, 14, 182, 235, 133, 3, 219, 15, 253, 106, 57, 221, 208, 12, 208, 125, 131, 23]
-----------------------------------------
[ 423.873441] sha384 digest: 524a1e46e61021264c74275be4225d03526dc6e033cd09d75d1359c7d6e54ed40b2dc21ee218c5516e1431161d7c9b24
RTMR 3: [245, 123, 183, 237, 130, 198, 174, 74, 41, 230, 201, 135, 147, 56, 197, 146, 199, 212, 42, 57, 19, 85, 131, 232, 204, 190, 57, 64, 242, 52, 75, 14, 182, 235, 133, 3, 219, 15, 253, 106, 57, 221, 208, 12, 208, 125, 131, 23]
I pondered for a while, and double checked my implementation against a patch recently submitted by Intel1, and another one used in OVMF2, before I decided to try simply changing my static buffer to a buffer allocated dynamically by kmalloc. Lo and behold, I finally got the correct extension in my RTMR.
And what prompted me to make such a guess? I had a suspicion that there was some issue with the address of my buffer.
I decided to load the compiled loadable kernel module into a disassembler to see what was going on.
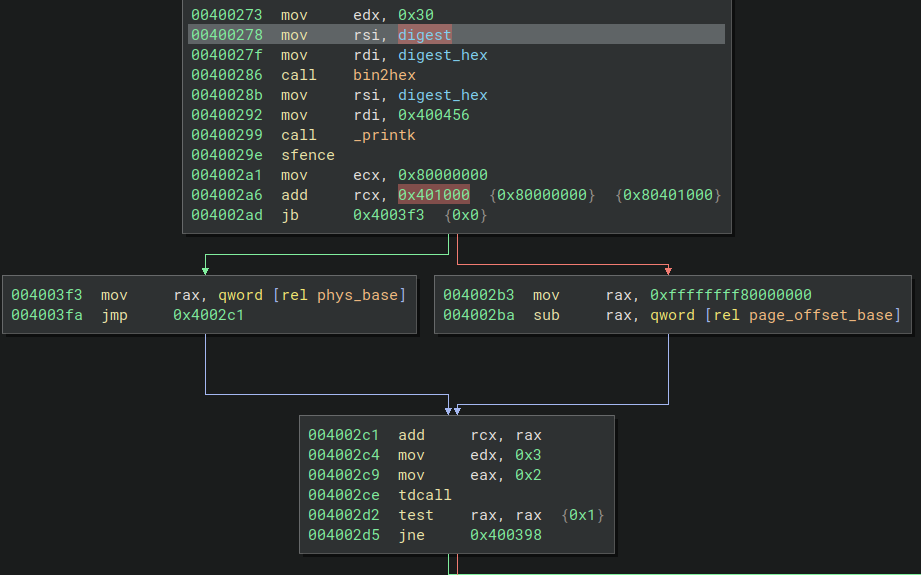
For the benefit of my friends who use screen readers, I’ve replicated this picture as a raw mermaid diagram, although unfortunately, it cannot show the variable that I have highlighted that shows the data-flow.
flowchart TD
%% ──────────────────────────────────────────────────────────
%% Basic blocks
%% ──────────────────────────────────────────────────────────
A["**0x400273**<br/>
mov edx, 0x30<br/>
mov rsi, digest<br/>
mov rdi, digest_hex<br/>
call bin2hex<br/>
mov rsi, digest_hex<br/>
mov rdi, 0x400456<br/>
call _printk<br/>
sfence<br/>
mov ecx, 0x80000000<br/>
add rcx, 0x401000<br/>
**jb 0x4003f3**"]
B["**0x4003f3**<br/>
mov rax, qword [rel phys_base]<br/>
**jmp 0x4002c1**"]
C["**0x4002b3**<br/>
mov rax, 0xffffffff80000000<br/>
sub rax, qword [rel page_offset_base]"]
D["**0x4002c1**<br/>
add rcx, rax<br/>
mov edx, 0x3<br/>
mov eax, 0x2<br/>
tdcall<br/>
test rax, rax<br/>
**jne 0x400398**"]
%% ──────────────────────────────────────────────────────────
%% Edges
%% ──────────────────────────────────────────────────────────
A -- "jb (carry‑set)" --> B
A -- "fall‑through" --> C
B --> D
C --> D
In the first basic block, you can see that the digest buffer is referred by a label in the disassembler, which is also called digest. The label is usually rendered by the disassembler if symbols are retained in the binary, and typically if its location is referenced using a relative offset like [rip + 0x401000]. In this particular scenario, the address of the digest buffer is at an offset of 0x401000 from the base address of the binary. The base address isn’t known until runtime, since kASLR exists.
However, seeing the instruction, mov ecx, 0x80000000 and add rcx, 0x401000, gave me the hint that a fixed offset was used rather than a relative offset, which would have been something like [rip + 0x401000] instead. So, somehow, a fixed address was given to virt_to_phys() instead.
The next two basic blocks, I believe, is the inlined function for virt_to_phys(). Seeing these 2 basic blocks also prompted me to look at the implementation of virt_to_phys() and I realised that I should have looked at the doucmentation before using the function - it did state that it is only valid to use this function on addresses directly mapped or allocated via kmalloc 3. But furthermore, i realised that the physical address is simply a subtraction4. Finally, in the last basic block, you’ll see add rcx, rax (this should be the last instruction from virt_to_phys()) - which basically adds the fixed value to the fixed address.
So, I wondered, what made an address by kmalloc special? How does it differ from vmalloc? This prompted my rabbit hole explorations to understand how memory is managed in linux kernel.
So i delved into linux kernel docs5 and was surprised to find that buddy allocator is actually used in linux kernel even today.
The last time I’d heard of the buddy allocator was back in university, during operating systems class. My assumption was that it was used in early versions of Linux, but I didn’t realise it was in fact, still being used today.
Buddy allocator is quite simple in the way it works - it gives you memory in the smallest power of 2 possible, with the smallest size typically being 64KB. As with any allocation system, external and internal fragmentation is a problem that needs to be considered.
External fragmentation happens when there are small blocks of free memory between allocated “buddy” blocks, but cannot be used because it is too small to fulfill a huge memory request. To deal with this issue, Linux kernel has an API called vmalloc, which allows you to use physically non-contiguous memory that maps contiguously in virtual memory6.
Interestingly, the documentation notes that huge memory requests are rare on Linux, and almost always can be served by using vmalloc, whose size is typically capped out at 128MB. And typically, this region of memory is used for swap info and loadable kernel modules. While kmalloc is used under the hood, accessing this region of memory is a bit more involved: when we want to access an address that resides in vmalloc region, the address is not stored on the main page table of the process. This causes a page fault, and the page fault handler knows to check a secondary structure that keeps track of vmalloc addresses that are used.
Internal fragmentation happens when the requested memory size is much smaller than the smallest block of memory that the allocator can give, such as requesting 32 bytes, but the smallest block size that an allocator can give might be 64KB. This is actually a big problem in buddy allocator, and the way Linux solves this problem is by using a SLUB allocator (an better version of the original SLAB allocator). The SLUB allocator splits the block up into smaller “slab” sizes and keeps track of full, partially used and free slabs. If there is not enough space left, it will request the buddy allocator for a new region of memory.
After this whole exploration, I’m particularly amazed by how simple the buddy allocator is, and also how efficient it is at combining free blocks with just a single bit. I’m going to end off with a digression of how it works at a high level:
Given 2 blocks A and B which are known to be buddies, and suppose we have a bool is_diff_state = 0 (to represent that both A and B are currently in the same state):
- Suppose we want to use block A:
- flip is_diff_state to 1.
- After that, supposed we want to use block B:
- flip is_diff_state to 0.
- Now we want to free block A:
- flip is_diff_state to 1.
- can we combine A and B? : No, because they’re both in different states.
- Nowe we free block B:
- flip is_diff_state to 0.
- can be combine A and B? : Yes, because they’re now both in the same state, they’re both free.
So now we’ve settled how blocks can be quickly combined when free. The next one is, how do we know if two blocks are buddies of each other? Given that in buddy algorithm, every allocation has to be a multiple of 2, and assuming every addressable unit is a page, this is quite simple: we can simply flip the kth bit to find the buddy.
For example:
- Assume that block A starts at page 0, and the block size is size 2 (ie, 1 block has a size of 2 pages). In binary, we can represent 2 as 0b10. Or equivalently,
1 << k, where 2^k = 2, which means in this case, k = 1. - Now we flip the kth bit using xor to find the buddy: 0b00 ^ 0b10 = 2. So its buddy block B starts at page 2.
- Supposed we start from block B instead, then the equation is as follows: 0b10 ^ 0b10 = 0. So the buddy block starts at page 0, which is exactly block A.
-
https://lkml.org/lkml/2025/2/12/1800 ↩
-
https://github.com/tianocore/edk2/blob/master/MdePkg/Library/BaseLib/X64/TdCall.nasm ↩
-
https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/io.h#L129 ↩
-
https://elixir.bootlin.com/linux/v6.14.5/source/arch/x86/include/asm/page_64.h#L22 ↩
-
https://www.kernel.org/doc/gorman/html/understand/understand009.html ↩
-
https://www.kernel.org/doc/gorman/html/understand/understand010.html ↩