Debugging Nested VM Crash
This post is about something that I debugged together with a friend sometime ago (around June-Sep 2020), but only decided to post about it much later as there is already a proper fix for this problem in the Linux Kernel, found in this commit.
Introduction
Before I delve into more details, I thought I should give a brief overview of how virtual machines work. Virtual machines typically run on top of a hypervisor, which can be of Type 1 (bare metal) or Type 2 (hosted). Type 1 hypervisors run directly on hardware, and a good example of this is Hyper-V. Type 2 Hypervisors on the other hand, run on top of an operating system - an example of this is Virtualbox.
On Linux, one of the more common choices for running a VM is via QEMU-KVM, which is the focus of this post. KVM, despite its unique architecture of being implemented as a loadable kernel module, is a Type 1 hypervisor. The core of it focuses on handling CPU things related to virtualization as supported by the hardware; things like memory management are done by the Linux kernel, and device emulation is done by its userspace component, QEMU. This results in a small code base for KVM, at approx 10k LoC at the time of writing. The hardware support (via Intel VMX for eg.) is a reason why virtual machines today can run at almost native speed - assembly instructions in your virtual machine are executed directly on the processor, and not translated by software!
Problem
I was trying to load a nested VM from a saved QEMU snapshot, where the snapshot contains the following:
- The VM that the host runs directly, also known as L1: A Linux OS, running either kvm or xen hypervisor1.
- The VM that L1 runs, also known as L2: Also Linux
I noticed that everytime I attempted to load the snapshot, it will alternately crash and fail to load. This was not acceptable for me as I wanted to reload the snapshot many times without it crashing half the time.
For reference, I was using Qemu 5.0 and running a custom Linux Kernel 5.4 where I had a script to compile and re-load kvm whenver I inserted any new debugging via printk(). For this post, I will focus on Intel CPU behaviour as well, as I was debugging on an Intel Processor.
Debugging
To start off, I first had to figure out how a virtual machine works on x86, especially one running under KVM. Thankfully, there were some pretty detailed documentation that I could find via the Intel Manual Vol 3C Part 3, The Turtles Project whitepaper and also this Nested Virtualization presentation by RedHat. It took me a while to try to digest the things that I needed to know, but to summarize, as most of the articles focused on how the Virtual Machine Control Structure (VMCS) is used and how it works, it seemed that I could focus the bulk of my debugging on it.
This VMCS contains a lot of information - guest state information, host state information, vm exit control fields, etc etc… In order to simplify my debugging, I omitted the case where VMCS shadowing (optimization) is present, as the concept behind how the system works remains the same, and yet the introduction of this makes the VM transitions more complex and difficult to debug and reason about.
In my problem listed above, there are 3 VMCS involved, VMCS01 and VMCS02 which run on the cpu, and VMCS12 which is virtual. The reason this is so is because in KVM (and possibly other hypervisors), any operation that causes the VM to trap will first exit to L0 (the host), which will then decide if the host itself needs to handle the operation, or it can delegate the work to another VM. VMCS12 is updated by KVM at specific points through the help of VMCS02, which I will elaborate more on later.
I made use of dump_vmcs() to dump the currently running vmcs. For VMCS12, this was a bit more tricky as it is virtual and actually resides in a struct instead of values we can dump from the CPU itself with vmread, but I decided to manually dump every field of the struct VMCS12 at the function nested_vm_enter_non_root_mode() as it seemed that there were some functions doing some preparation there2.
I also compared the VMCS to when it is first loaded by QEMU in the following process:
- Qemu: calls
kvm_put_nested_state(). This later leads to an ioctl called with the flagKVM_SET_NESTED_STATE.3 - KVM: The function call chain goes from
kvm_vcpu_ioctl->kvm_set_nested_state(I dumped VMCS12 here too) ->enter_vmx_operation->nested_vmx_enter_non_root_mode
It proved to be fruitful as I noticed some corruption of values in VMCS12, or values that did not look right compared to when it was loaded from snapshot. In particular, the register values that were wrong were all those listed in sync_vmcs02_to_vmcs12_rare(). This function is only executed when the variable nested.need_sync_vmcs02_to_vmcs12_rare = true
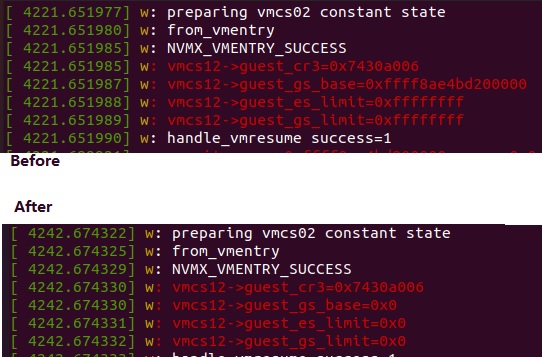
In the image above, for the part “before”, I printed a few of the register states in VMCS12 when I first loaded the snapshot from disk. Then, I restored the VM to the snapshot, resulting in the “after” state, where some registers had a 0 value instead of the original value. All printing is done via printk and displayed with dmesg.
I started looking more into flow of the whole process in order to figure out why this happens. After a lot of debugging, my friend and I came to realise how the VMCS updating system works. There are just 2 cases we need to consider.
What does KVM do when:
- L2 performs an operation that causes a trap to L0.
- vmcs02 gets updated as it runs on the CPU
- In
enter_vmx_operation(), the variablenested.need_sync_vmcs02_to_vmcs12_rareis set to true so that L1 can receive its L2 guest’s changes at a later timing, especially if it is not going to access vmcs12 immediately. - I believe this “delayed write” is an optimization on the part of the developers. From the commits, it seems that not writing rarely accessed fields immediately saves ~200 CPU cycles.
- L1 wants to interact with L2.
- When L1 attempts to do any operation on vmcs12, such as a vmread/vmwrite, this operation causes a trap to L0
- If
nested.need_sync_vmcs02_to_vmcs12_rareis set to true,sync_vmcs02_to_vmcs12_rare()happens first. - After that, the actual reading and writing to vmcs12 happens.
- Then, L0 updates vmcs02 from vmcs01 and vmcs12.
When we saved the virtual machine state to disk, the state of vmcs02 was already flushed into vmcs12, and saved in our snapshot. Thus, when we load the snapshot, vmcs12 is already correct and does not need to be synced again. So then, why was nested.need_sync_vmcs02_to_vmcs12_rare set to true?
This was the sequence of events that happened in reality:
- On the host, we load our snapshot, unpause L1, and within L1, unpause L2. As L2 would not yet be initialized on the host, KVM allocates space for structs related to L2.
- (optional) Pause L2 from within L1. This operation causes a vmexit, and
nested.need_sync_vmcs02_to_vmcs12_raregets set to true, since there will be a change in state of vmcs02 when L2 gets paused. If this step is not executed, there is still a high chance of this variable being set to true as there is constant context switching between the VMs happening. - On the host, re-load the snapshot. This causes vmcs02 to be reset to uninitialized values. VMCS12 goes back to what it was in the saved VM state.
- We unpause L1 from the host, then from within L1, we unpause L2. This is essentially a vmlaunch on vmcs12, which causes a trap to the Host. As
nested.need_sync_vmcs02_to_vmcs12_rareis True, vmcs12 gets updated with uninitialized vmcs02 values. L0 then merges vmcs01 and vmcs12 to make a new vmcs02. - When L2 attempts to run, the register state from vmcs12 is not completely correct, so it crashes. This causes a trap back to L0 with the exit reason, and all structures related to the L2 VM is then freed on KVM.
Solution
To fix the problem, we explicitly reset nested.need_sync_vmcs02_to_vmcs12_rare to false at the loading of snapshot time.
In the function enter_vmx_operation(), just before the return statement, insert the following line:
vmx->nested.need_sync_vmcs02_to_vmcs12_rare = false;
Footnotes
-
I’ve tested that Hyper-V and Windows can also be used, but debugging would be more complex. ↩
-
Actually, the crash can also be checked on your L1 host if debug printing is enabled. For example, if Xen hypervisor is running on L1, you can do this via
sudo xl dmesg. ↩ -
Actually, when a snapshot is loaded, we noticed that QEMU makes at least 4 important ioctl calls with the following flags in this sequence:
KVM_SET_NESTED_STATE,KVM_SET_NESTED_STATE,KVM_GET_NESTED_STATE,KVM_SET_NESTED_STATE. This is not super useful when we were debugging, but this order of ioctl execution is important for why the solution committed at the start of this post works - as the fix was implemented in the functions related to the GET, the GET has to happen before a SET . ↩